

Hearthstone decks with word embeddings
Introduction
Hearthstone is a notorious digital collectible card game developed by Blizzard, boasting an impressive user base of more than 70 millions players worldwide. I am one of them. I have been playing through ups and downs since 2013 and despite not being by any means a good player I posses a vast knowledge of the game. Which may sound as a meagre satisfaction to many, yet it brings a great deal of fun and engagement to me personally.
Among other things, I am also a machine learning enthusiast, constantly hungering on new side projects to develop in my spare time. Ideas grow, flourish and die quickly in my brain, yet some of them are more resilient and manage to stick through, leaving me thinking about them for days at a time. This was one of them. It aims to couple my passion for the game to my scientific curiosity for AI. I hope it can arouse in you that satisfying “Ah-ah!” moment as it did in me.
The aim of this project is then twofold: first, to explore how Hearthstone cards can be encoded for machine learning tasks and then to generate cohesive Hearthstone decks programmatically.
Notice: this article requires you to be familiar with the concept of neural networks. If you are not, this page will explain the bare minimum. Additionally, if you want a more detailed and insightful reading with plenty of linear algebra and fancy graphs and python, then this is the place to go.
Word embeddings
Before starting, I feel compelled to briefly introduce word embeddings and their properties, which will make it more clear why I chose this technique to approach the problem in the first place. I won’t delve too much into details because this tool is widely known and there are several lengthy articles out there that better describe the whole mathematical fluff behind it with insightful and exhaustive examples.
Long story short, “word embeddings” is a name that refers to several techniques and algorithms used in the context of natural language processing, whose aim is to transform words (or more generally strings) into vectors. The advantage of such transformation should be apparent, since it is much easier for machine learning tools to work on vectors of numbers rather than strings. The process of mapping a “point” in the string domain (i.e. a “word”) to a point into a usually high-dimension space is called embedding. The magic behind an embedding is less surprising than one could expect, as it is largely based on clever manipulation of word frequencies.
Surprisingly, once mapped into a higher-dimension space, word-vectors exhibit outstanding geometrical properties that reflect the original meaning of the words themselves! For example, words with similar meaning like “good”, “great”, “awesome” will probably be mapped into neighbouring points and will likely be very distant to other words with opposite meaning like “bad”, “awful”, “terrible”. Additionally, relationships between similar concepts would likely yield similar geometrical distances:
Vector("queen") - Vector("woman") ~ Vector("king") - Vector("man")
The insight behind such amazing behaviour can be summarized with the intuition that similar words appear in similar contexts, which is made more apparent upon learning how the problem is approached.
The two most prominent approaches to the problem are continuous bag of words (CBOW) and skip-grams. While the former aims at predicting a word given its context, the latter wants to predict the whole context given a single world. In these statements, context has an intuitive meaning that many can easily grasp without explanation: it loosely indicates the set of words that are nearby a given target word. For example, in the sentence “the quick red fox jumped over the lazy brown dog”, “the quick red - jumped over the” is the context of the single word “fox”. Of course, in reality it’s a bit more complex than that since you usually want to skip ancillary words that convey little to no meaning, like “the”, or be able to merge very similar tenses of the same verb (“jumps”, “jump”, “jumped”) or singular/plural cases (“fox”, “foxes”). Getting rid of textual noise is a menial task of NLP which is solved by notorious techniques like tokenization, stop-words pruning, stemming and lemmatizing. Luckily, in this project, we won’t be needing any of that!
Word2vec is an algorithm developed by Google that implements CBOW and skip-grams with a feed-forward neural network. Given a sufficiently large corpus to train on, the algorithm will eventually learn to predict words given their context or vice-versa, ultimately equipping us with a magical function that can map words to vectors in a mystical vector space. I should clarify that it requires some hyperparameters in input, like the length of the context to consider and the dimensionality of the output vectors: these values depend on the specific problem and are left to the developer to choose.
Now it’s time to connect the dots and link the abstract concept of word embeddings to the task of generating Hearthstone decks!
Cards as words
Given I do not delve into deep machine learning tasks every day, it is necessary for me to refresh my memory every once in a while. Thus I found myself reading about word embeddings again… for the fourth-ish time. I cannot complain, since it’s one of the most fascinating tools of NLP. Anyway, it stroke me that the reason behind words appearing close together in the mapped vector space essentially resides in the similarity between their contexts. It got me thinking… what if I represent Hearthstone cards as words? And, by extension, decks as sentences? This intuition is the foundation of the experiment I am going to illustrate.
The assumption sounded reasonable, since it’s sensible to presume that “similar” cards will end up in “similar” decks. It is often the case that people ask for advice to replace one or more cards from famous deck recipes, since they do not own such cards yet. Now, the concept of similarity is very loosely defined - more by intuition than by rigor. Some cards may often appear together because they have synergies:


or because they have the same mechanic:


or simply because they are strong parts of the class identity:


Thus we have to take the concept of similarity with a grain of salt (without being too salty) and with a pinch of good old criticism.
After validating my initial ideas, I considered that it would be quite easy to embed Hearthstone cards into a vector space. Essentially, each deck is like a sentence: it tells us a story about what it wants to accomplish and how it plans to do so. Cards are like words used to describe the story. The most enticing part is that, by design, all Hearthstone decks must have a fixed number of 30 cards (I am only considering constructed format here), which presents itself as a very nice number to define the length of a context!
Creating a corpus of decks
The first step is then obvious: collect a big number of decks to create the base corpus on which word2vec will be trained to produce the final embedding. This process was quite lengthy and a bit clunky because of various technical limitations. However, in the end I managed to accrue about fifteen thousands decks, assembled by the community over the span of several years. Bear in mind that this dataset is unbalanced and heterogeneous:
- it contains both recent and old decks, yet some cards have changed over the course of time and their context may have shifted. A notable example is Fiery War Axe, which was a staple card in every Warrior deck until it got nerfed to 3 mana, which caused its premature disappearance from the constructed scene;
- it contains much more recent decks than old ones. This is a drawback of the collection process that can be addressed with a more scrupulous dedication to gathering decks in a balanced fashion;
- it contains both standard and wild decks.
Point 2 and 3 can easily be addressed by spending more time in the data collection process. It would be interesting to see how results change with more cohesive datasets and you are welcome to try and perform your own version of the experiment!
TLDR: I really wanted to get my hands on results as quickly as possible to validate my ideas and check the feasibility of the next phase!
Building a card embedding
After creating my dataset, it was just a matter of processing it to output data in a format word2vec understands. I won’t annoy you with the more trivial details. Just bear in mind that I only considered decks with exactly 30 cards: it is possible to have less than that number while building decks for Brawl mode; these have been discarded. I ran word2vec and a few seconds later, my embedding was ready. Yay!
Notice: you can find all the hyperparameter values and technical details in the source code at the end of the article.
Well… word2vec only produces a lump of python objects, which are not exactly intelligible by a human. Thus I decided to apply a very common visualization and dimensionality-reduction technique by passing the whole transformed card-vectors into t-SNE. If you are not familiar with it, I suggest you read this amazing article. In layman terms, it takes a bunch of points from a very high-dimension space (which is our case since card-vectors live in a 16-dimensions space) and tries to visualize their structural layout in something more affordable and human-readable, like a 2-D chart. Note that the x and y coordinates do no have any particular inherent meaning a-priori, they are just an easily approachable canvas for the algorithm to paint on. Here are my results:
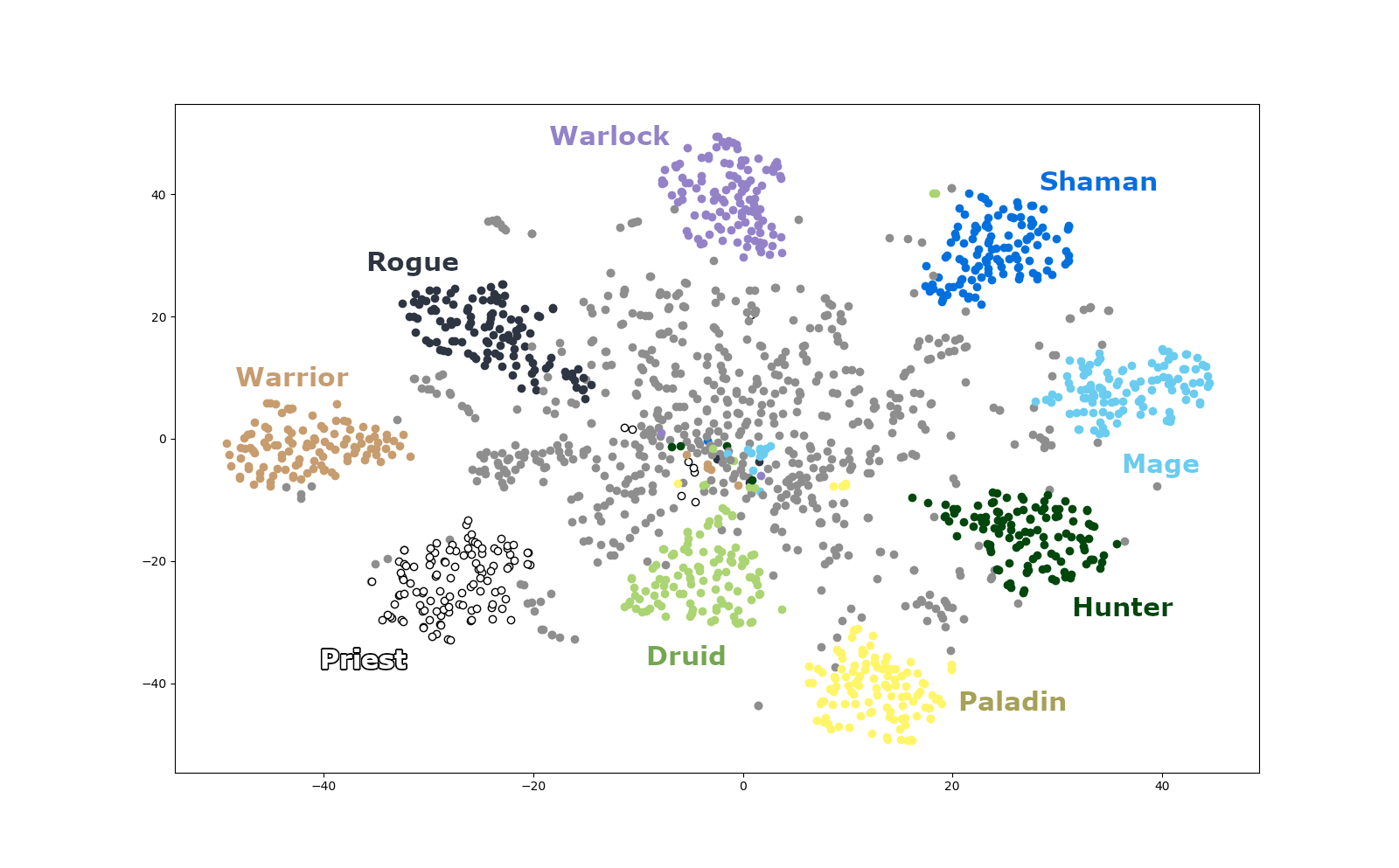
You can clearly see nine colored clusters that represent the nine hero classes in Hearthstone, with a more sparse lump of grey points that radiate from the center, which represent neutral cards instead. The results of visualization were extremely pleasing and told me that my idea was a sensible approach to the problem. Now, t-SNE is a very powerful technique and allows to easily interpret high-dimensional data that human could not otherwise fathom. However it has some drawbacks: artifacts and relations we see in the chart do not necessarily imply an underlying connecting structure in data! This is especially dangerous since humans naturally tend to see order where there is none. For example, cluster sizes and inter-cluster distances may not mean anything, but they may be a mere circumstantial byproduct of the derived topology. I am no expert in the field and surely data scientists that are reading this article may find additional insights or flaws in my reasoning, yet I will try to explain some interesting arrangements of points.
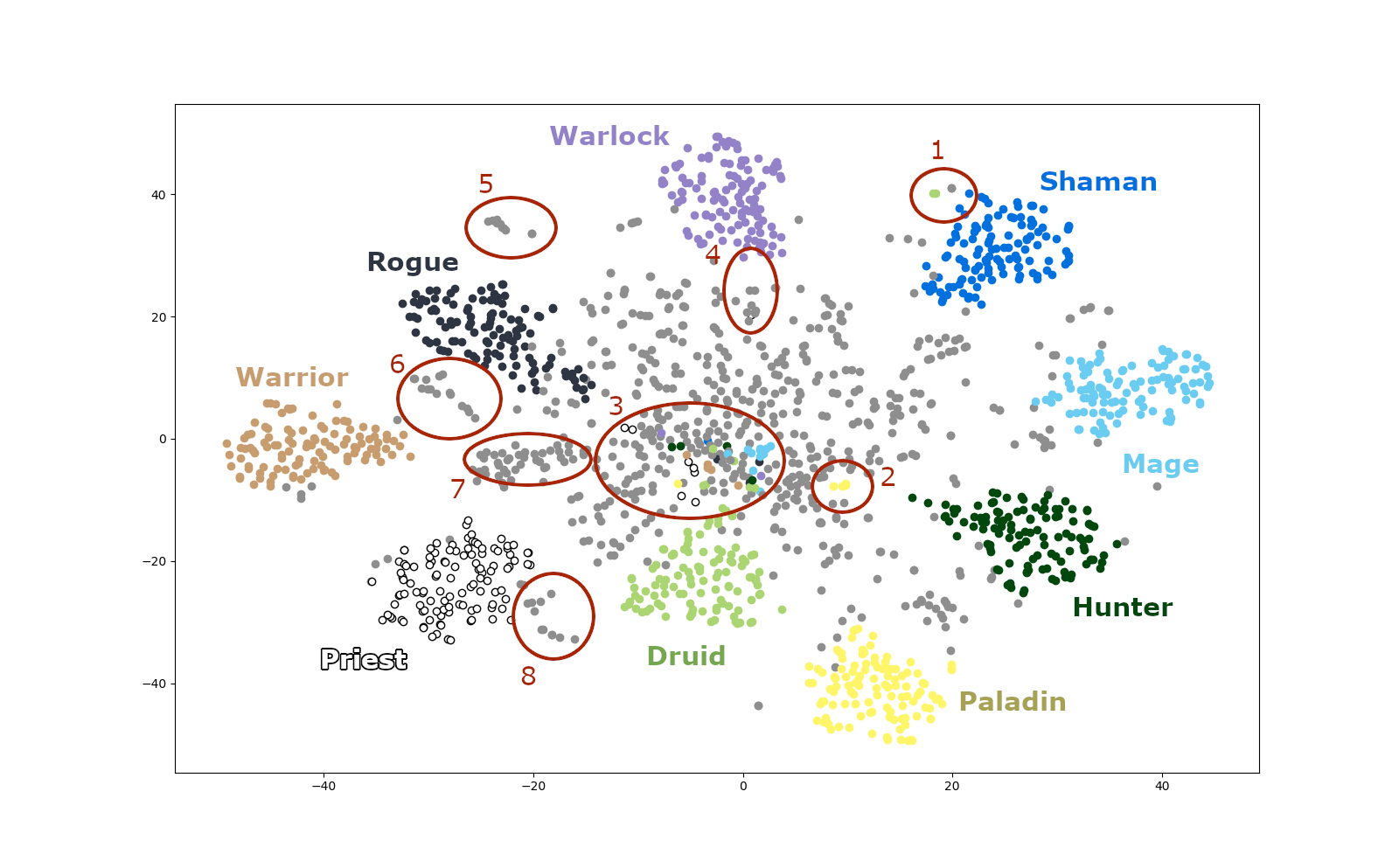
Most clusters appear to be well-formed and consistent, with class-specific cards separated from neutral cards. Yet some areas of the chart are very interesting. I numbered them from 1 to 8. Let’s discuss them!
Let’s start with number 7:
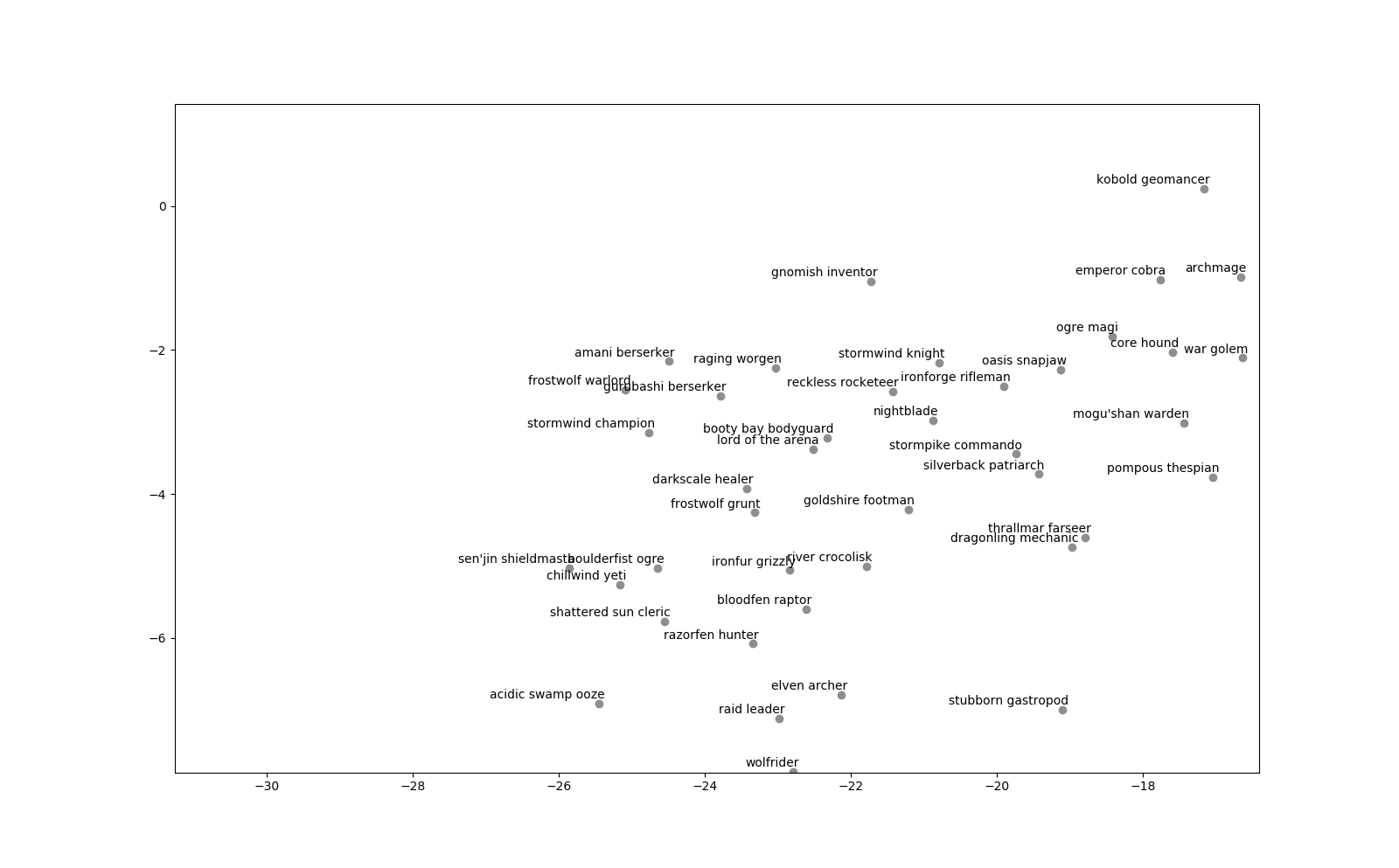
Wait a second… aren’t those mostly cards from the basic set? Interesting! They got clumped together very nicely, with the notable exception of Pompous Thespian. I wonder how it ended up in that cluster. Then how about number 8?
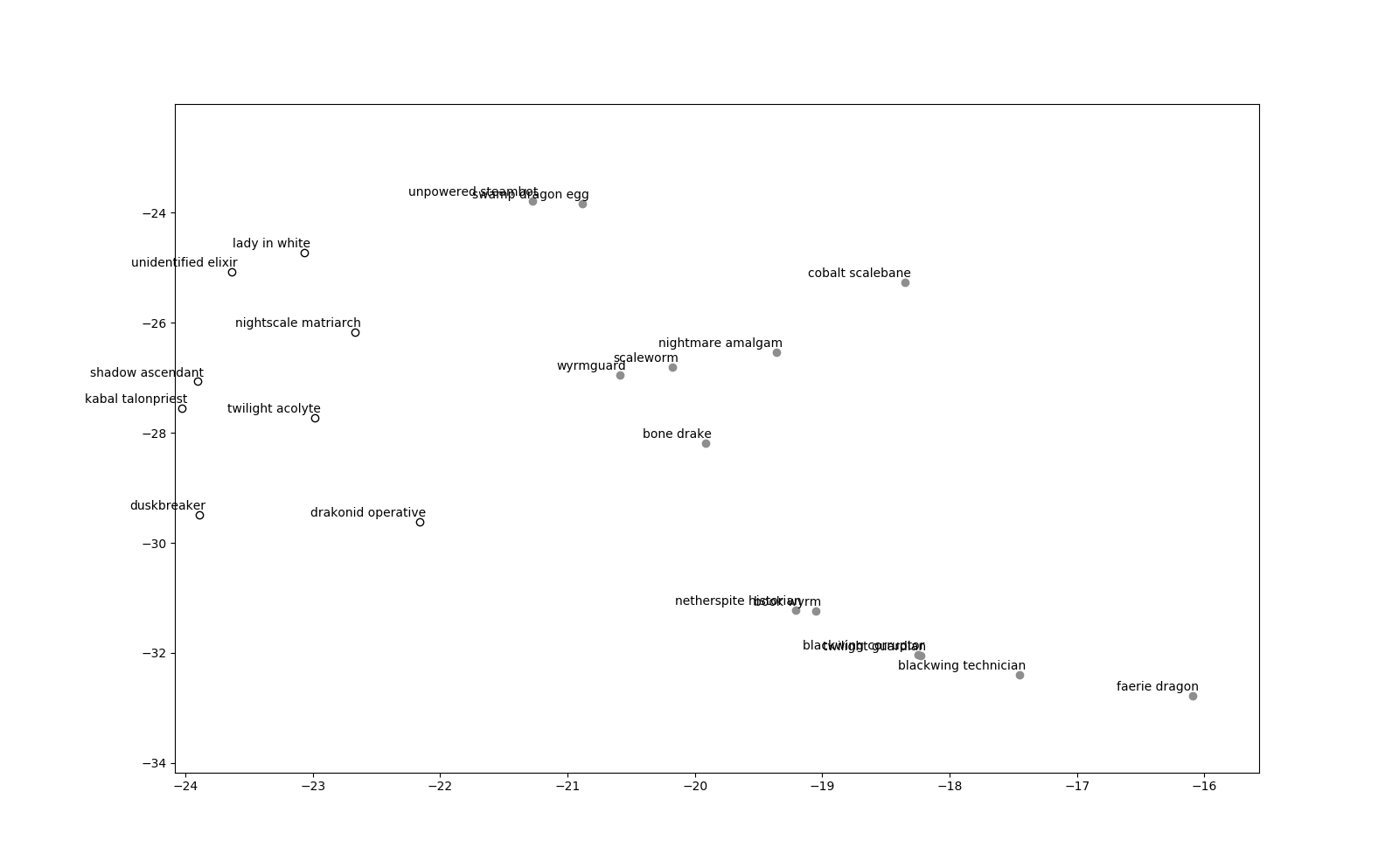
That sounds oddly familiar. I wonder why so many dragon-type cards got plotted near the priest cluster. It’s surely not because of any dragon priest deck, mh? What about area number 6?

We see many pirate cards, which got interestingly placed between the warrior and rogue clusters. Then some more rogue-flavoured characters like the Hench Clan Thug and Leeroy Jenkins. Finally, in area 5 we have some C’Thun cards. But all of these are fairly predictable, right? Cards with the same context get bundled together and t-SNE just shows us an inherent property of deck-building. I am more interested in the anomalies numbered 1 to 4.
In 1, you can clearly see two druid cards that appear near a shaman cluster. Dare to take a bet? No? Let’s zoom in:
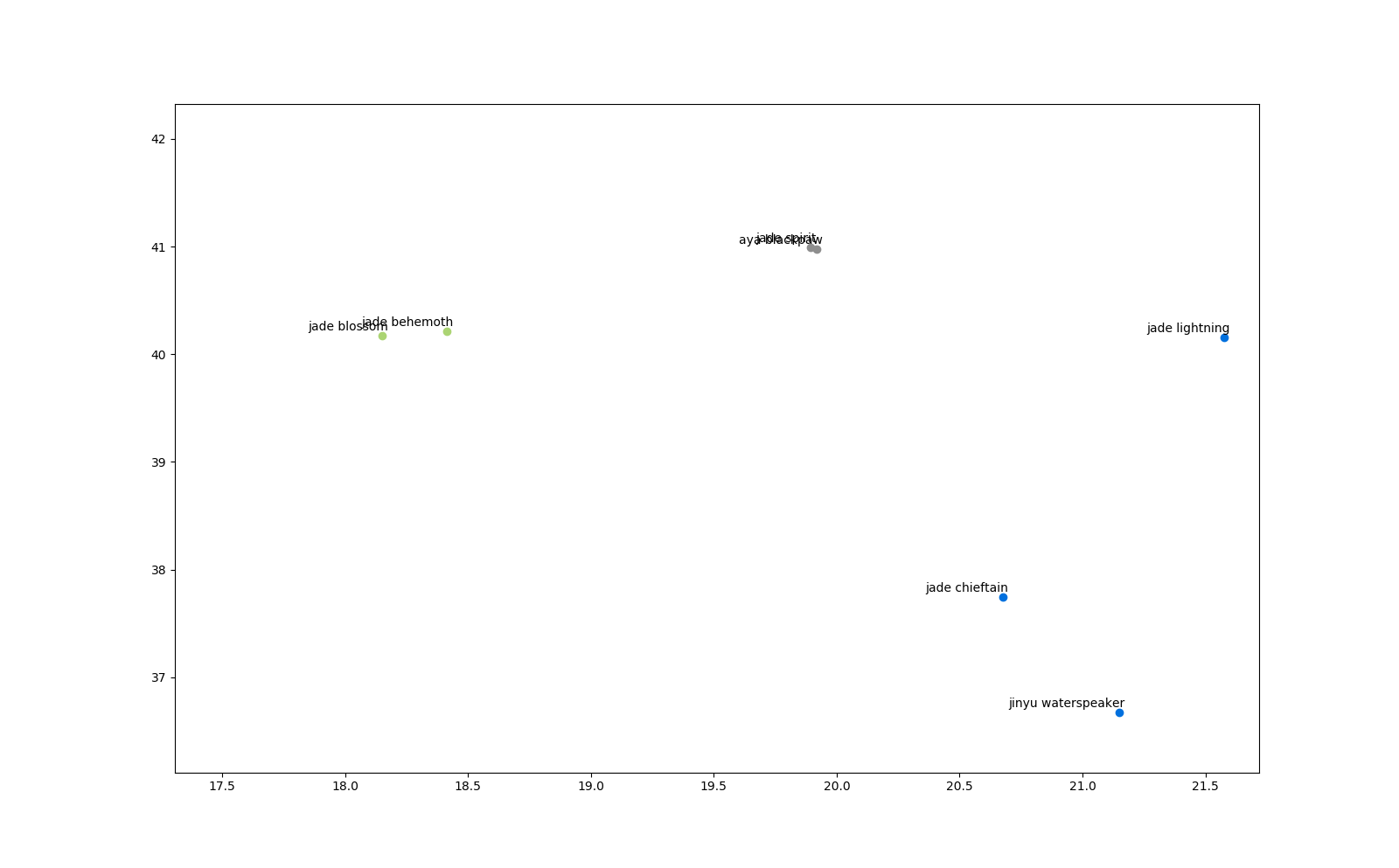
Interestingly, all those cards but one are jade-related (and even the one outlier belongs to the same expansion set). Some are neutral, some are class-specific. It is sensible for them to be close because they share a common theme. Now, don’t be fooled by over thinking about the positioning. Even though those two druid outliers are so far from the druid cluster, it does not mean they are more special. I think that the “bond” they share with Aya Blackpaw, i.e. their context, is stronger than the one that linked them to other druid cards. Recall that t-SNE can be misleading! More plotting at several level of perplexity may be needed to fully appreciate the more complex facets of the embedding. Since we are forcing so many dimensions onto a 2D plot, it’s natural that something is lost. Maybe those points are all close together AND close to the druid cluster in 16 dimensions! In fact, directly querying the card-space yields these results:
Cards close to Jade Behemoth:
0.9295 Jade Blossom
0.8986 Jade Spirit
0.8906 Fandral Staghelm
0.8394 Jade Chieftain
0.8154 Aya Blackpaw
0.7991 Jade Idol
0.7721 Jade Lightning
0.7200 Lotus Agents
0.6781 Feral Rage
0.6407 Jade Swarmer
Hidden beneath a couple of grey dots there is a tight group of priest cards sneaking near the warlock cluster at number 4. This is another instance of the same phenomenon. They are Humongous Razorleaf and Purify. My hypothesis is that they are tightly coupled with Ancient Watcher and Sunfury Protector because they appear together in silence priest archetypes. However, the latter two cards also used to appear very frequently together in early zoo warlock decks! Moving onto 2:

We notice there are several paladin cards that are detached from the paladin cluster. My hypothesis is that those cards occur very few times because they are notably considered sub-optimal and thus they have less “class identity” than others. Then what about the many coloured dots near the center of the plot? What about number 3?
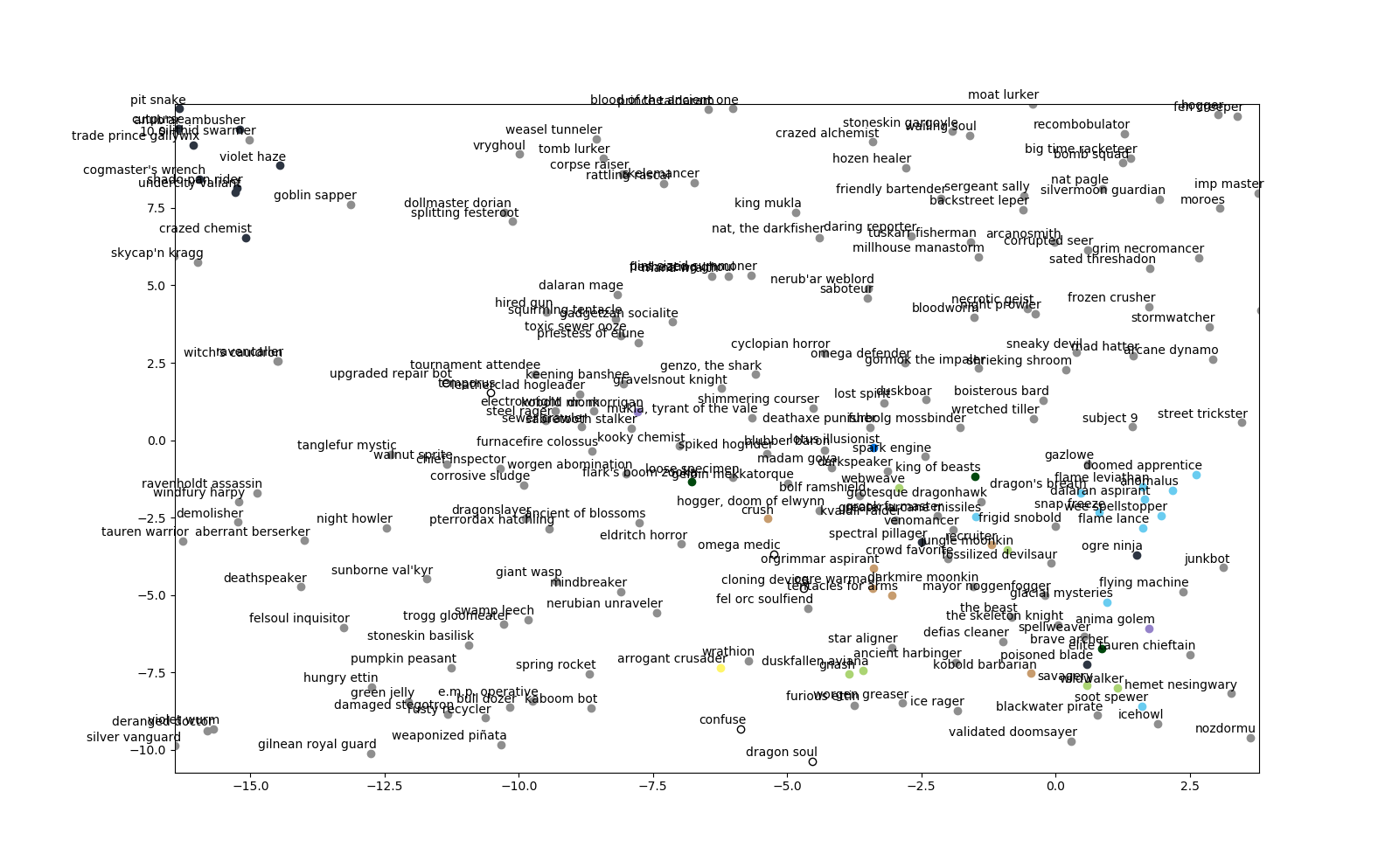
I’ll let you judge for yourself on this. I see a lot of cards that have been played very little:



Interestingly, Subject 9 is there too. I thought secret hunter was a thing. Maybe I was mistaken! After all, I do not follow the professional scene so often. Anyway, to draw some conclusions on this amazing chart, I would dare to hypothesize that cards closer to the center suffer from either little class identity or low play rate, maybe because they are just awful, or maybe because there is no inherent synergy with any other card printed so far. On the contrary, cards the are located at the very limit of existing clusters are strong gameplay defining or very archetypal cards.
Generating new decks
Equipped with the geometrical knowledge of card-embedding, I started thinking at how to generate new decks automatically. This is a purely academical experiment, of course: human crafted decks will remain stronger and more consistent because we are only basing our assumption of consistency on a vague definition of “closeness” which is only defined on top of (mostly sub-optimal) user-generated content. Anyway, it’s a fun experiment to try! My first thought was to train a generative adversarial network (GAN), because it’s 2018 and it’s trendy. You have most likely heard of neural networks that generate cat faces or even music. On a second reflection, I considered that GANs have to learn the core concepts of the problem from the ground up every time. On top of that, the generator is usually a vector of white noise, i.e. data that makes no sense at all. From such input, the network has to infer something that instead makes sense. It is a massive effort. So, why would I want to spend hours of training when I already have a geometric understanding of the space in which card-vectors live? My solution was then much more trivial:
- Pick a random card X. Add it to the deck;
- Pick another card that is close to X in the embedded space and add it to the deck too;
- Repeat the process by picking close matches to cards already in the deck.
This algorithm is very dumb, yet very easy to implement and produces results straight away. There is only one parameter to tune, that I called alpha, since I lack creativity. On a second thought, I may have called it whackiness, for a reason that will be apparent in a minute. Alpha controls how far away the algorithm is willing to go when picking the next neighbour: if alpha is 0, then it will only pick the very best match each time; instead, if it is 1, it will pick any random point within the closest 30 neighbours. Want to see the results? Here are some with alpha = 0:
Mage deck created around Frostbolt:
1 x Frostbolt
1 x Archmage Arugal
1 x Pyros
2 x Ice Walker
1 x Leyline Manipulator
1 x Stargazer Luna
2 x Vex Crow
2 x Cryomancer
2 x Unexpected Results
2 x Book of Specters
1 x Toki, Time-Tinker
2 x Mana Wyrm
2 x Arcane Intellect
1 x Shimmering Tempest
1 x Steam Surger
2 x Primordial Glyph
1 x Frost Lich Jaina
2 x Dalaran Aspirant
1 x Arcane Explosion
1 x Lesser Ruby Spellstone
1 x Shifting Scroll
Druid deck created around Living Roots:
2 x Living Roots
1 x Floop's Glorious Gloop
2 x Innervate
2 x Raven Idol
1 x Poison Seeds
1 x Druid of the Swarm
1 x Dark Wispers
1 x Grove Tender
1 x Darnassus Aspirant
1 x Tree of Life
2 x Forbidden Ancient
1 x Volcanic Lumberer
1 x Claw
1 x Starfall
2 x Lunar Visions
2 x Wrath
2 x Bite
1 x Malorne
1 x Mark of Nature
1 x Mire Keeper
1 x Wild Growth
1 x Mulch
1 x Druid of the Saber
Well, these are by no means tier 1 decks! But there are some synergies that you can easily spot. After all, the algorithm is clearly not aimed at optimizing the result. If I wanted good results, I’d have picked the closest match to all other cards at every step, which does not guarantee optimality but at least tries to capitalize on the learnt concept of “closeness”. Here is one with alpha = 1:
Rogue deck created around Fire Fly:
1 x Fire Fly
1 x Fungalmancer
2 x Igneous Elemental
2 x Glacial Shard
1 x Ozruk
1 x Fallen Sun Cleric
2 x Tol'vir Stoneshaper
1 x Mad Hatter
2 x Ravencaller
1 x Servant of Kalimos
1 x Tar Creeper
2 x Cauldron Elemental
2 x Fire Plume Phoenix
1 x Boisterous Bard
1 x Sneaky Devil
1 x Wretched Tiller
1 x Piloted Reaper
1 x Spring Rocket
2 x Upgradeable Framebot
1 x Wargear
1 x Blazecaller
1 x Coppertail Imposter
1 x Replicating Menace
You can see why I wanted to call alpha whackiness instead. The higher it is, the higher the chance for a wider space exploration, which means you can end up very far away from the initial point!
I also tried to generate decks with a global-best choice, but I was a bit disappointed in the results. This is due to how the embedding is built. Let’s pick an (in)famous card - the Shudderwock - and look at its closest neighbours:
Cards close to Shudderwock:
0.9372 Grumble, Worldshaker
0.9052 Mana Tide Totem
0.9048 Murmuring Elemental
0.9007 Healing Rain
0.8996 Volcano
0.8923 Hagatha the Witch
0.8768 Hex
0.8761 Witch's Apprentice
0.8577 Bogshaper
0.8549 Lightning Storm
0.8260 Spirit Echo
0.8186 Voodoo Hexxer
0.8064 Blazing Invocation
0.8017 Jinyu Waterspeaker
0.7941 Omega Mind
0.7892 Tidal Surge
0.7886 Sandbinder
0.7686 Far Sight
0.7577 Kalimos, Primal Lord
0.7526 Zap!
0.7494 Fire Plume Harbinger
0.7368 Thrall, Deathseer
0.7351 Hot Spring Guardian
0.7255 Unstable Evolution
0.7241 Avalanche
0.7153 Stormforged Axe
0.7135 Thing from Below
0.7117 Hyldnir Frostrider
0.7097 Unite the Murlocs
0.7092 Crushing Hand
0.7087 Electra Stormsurge
0.7084 Cryostasis
0.7044 White Eyes
0.7041 Brrrloc
0.7024 Devolve
0.6997 Storm Chaser
0.6977 Stone Sentinel
0.6942 Moorabi
0.6937 Ice Breaker
0.6934 Master of Evolution
0.6859 Frost Shock
0.6817 Earth Shock
0.6808 Al'Akir the Windlord
0.6762 The Mistcaller
0.6756 Ghost Light Angler
0.6704 Jade Chieftain
0.6702 Lifedrinker
0.6679 Fire Elemental
0.6679 Hallazeal the Ascended
0.6679 Earthen Might
0.6665 Saronite Chain Gang
So, the first cards make sense, but we have to scroll way down to reach Saronite Chain Gang, which is a staple in that kind of decks. My supposition about this seemingly bizarre behaviour is the following:
- The dataset contains decks that date back to the beta, albeit fewer in number, which steers the expected results awry;
- Of course, the dataset does not contain only standard decks, which further contribute to modifying the embedded vectors;
- Lastly, decks in the dataset are not weighted. So a deck that had millions of views counts as one “sentence”, and a deck that is barely used at all counts the same. This is partly countered by the fact that there are many versions of more successful decks, yet the scaling is way lower than it would be if I considered plain numbers instead of single deck occurrences. Whether this is a better or worse approach can be discussed. I am not sure.
Anyway, all things considered it has been a very fun experiment!